Глава 8: Управление памятью
Эффективное управление памятью крайне важно для интеллектуальных агентов, чтобы сохранять информацию. Агентам требуются различные типы памяти, как и людям, для эффективной работы. В этой главе рассматривается управление памятью, в частности, требования агентов к немедленной (краткосрочной) и постоянной (долгосрочной) памяти.
В агентных системах память относится к способности агента сохранять и использовать информацию из прошлых взаимодействий, наблюдений и опыта обучения. Эта возможность позволяет агентам принимать обоснованные решения, поддерживать контекст разговора и улучшаться со временем. Память агентов обычно подразделяется на два основных типа:
Краткосрочная память (контекстная память): Подобно рабочей памяти, она хранит информацию, которая в настоящее время обрабатывается или недавно была доступна. Для агентов, использующих большие языковые модели (LLM), краткосрочная память в основном существует в контекстном окне. Это окно содержит последние сообщения, ответы агента, результаты использования инструментов и размышления агента из текущего взаимодействия, все это информирует последующие ответы и действия LLM. Контекстное окно имеет ограниченную емкость, что ограничивает количество недавней информации, к которой агент может получить прямой доступ. Эффективное управление краткосрочной памятью включает сохранение наиболее релевантной информации в этом ограниченном пространстве, возможно, с помощью таких методов, как суммирование старых сегментов разговора или выделение ключевых деталей. Появление моделей с "длинными контекстными" окнами просто расширяет размер этой краткосрочной памяти, позволяя хранить больше информации в рамках одного взаимодействия. Однако этот контекст все еще является временным и теряется после завершения сессии, а его обработка может быть дорогостоящей и неэффективной каждый раз. Следовательно, агентам требуются отдельные типы памяти для достижения истинной постоянности, воспоминания информации из прошлых взаимодействий и построения долговечной базы знаний.
Долгосрочная память (постоянная память): Она действует как хранилище информации, которую агентам необходимо сохранять в различных взаимодействиях, задачах или в течение продолжительных периодов, подобно долгосрочным базам знаний. Данные обычно хранятся вне непосредственной среды обработки агента, часто в базах данных, графах знаний или векторных базах данных. В векторных базах данных информация преобразуется в числовые векторы и сохраняется, что позволяет агентам извлекать данные на основе семантического сходства, а не точного соответствия ключевых слов — процесс, известный как семантический поиск. Когда агенту нужна информация из долгосрочной памяти, он запрашивает внешнее хранилище, извлекает релевантные данные и интегрирует их в краткосрочный контекст для немедленного использования, таким образом сочетая предыдущие знания с текущим взаимодействием.
Практические применения и случаи использования
Управление памятью жизненно важно для агентов, чтобы отслеживать информацию и работать интеллектуально с течением времени. Это необходимо агентам для превышения базовых возможностей ответов на вопросы. Применения включают:
Чат-боты и разговорный ИИ: Поддержание потока разговора зависит от краткосрочной памяти. Чат-ботам необходимо помнить предыдущие пользовательские вводы для предоставления связных ответов. Долгосрочная память позволяет чат-ботам вспоминать пользовательские предпочтения, прошлые проблемы или предыдущие обсуждения, предлагая персонализированные и непрерывные взаимодействия.
Агенты, ориентированные на задачи: Агенты, управляющие многошаговыми задачами, нуждаются в краткосрочной памяти для отслеживания предыдущих шагов, текущего прогресса и общих целей. Эта информация может находиться в контексте задачи или временном хранилище. Долгосрочная память критически важна для доступа к конкретным данным, связанным с пользователем, которые не находятся в непосредственном контексте.
Персонализированные опыты: Агенты, предлагающие индивидуальные взаимодействия, используют долгосрочную память для хранения и извлечения пользовательских предпочтений, прошлого поведения и личной информации. Это позволяет агентам адаптировать свои ответы и предложения.
Обучение и улучшение: Агенты могут улучшать свою производительность, обучаясь на прошлых взаимодействиях. Успешные стратегии, ошибки и новая информация сохраняются в долгосрочной памяти, способствуя будущим адаптациям. Агенты обучения с подкреплением хранят изученные стратегии или знания таким образом.
Поиск информации (RAG): Агенты, предназначенные для ответов на вопросы, получают доступ к базе знаний — своей долгосрочной памяти, часто реализованной с помощью Retrieval Augmented Generation (RAG). Агент извлекает релевантные документы или данные для информирования своих ответов.
Автономные системы: Роботы или самоуправляемые автомобили требуют память для карт, маршрутов, местоположений объектов и изученного поведения. Это включает краткосрочную память для непосредственного окружения и долгосрочную память для общих знаний об окружающей среде.
Память позволяет агентам поддерживать историю, учиться, персонализировать взаимодействия и управлять сложными, зависящими от времени проблемами.
Практический код: Управление памятью в Google Agent Developer Kit (ADK)
Google Agent Developer Kit (ADK) предлагает структурированный метод управления контекстом и памятью, включая компоненты для практического применения. Твердое понимание Session, State и Memory в ADK жизненно важно для создания агентов, которые должны сохранять информацию.
Как и в человеческих взаимодействиях, агентам требуется способность вспоминать предыдущие обмены для ведения связных и естественных разговоров. ADK упрощает управление контекстом через три основные концепции и связанные с ними сервисы.
Каждое взаимодействие с агентом можно рассматривать как уникальную нить разговора. Агентам может потребоваться доступ к данным из более ранних взаимодействий. ADK структурирует это следующим образом:
- Session: Индивидуальная нить чата, которая регистрирует сообщения и действия (Events) для этого конкретного взаимодействия, также сохраняя временные данные (State), релевантные для этого разговора.
- State (session.state): Данные, хранящиеся в Session, содержащие информацию, релевантную только для текущей активной нити чата.
- Memory: Поисковое хранилище информации, полученной из различных прошлых чатов или внешних источников, служащее ресурсом для извлечения данных за пределами непосредственного разговора.
ADK предоставляет специализированные сервисы для управления критически важными компонентами, необходимыми для создания сложных, сохраняющих состояние и контекстно-осведомленных агентов. SessionService управляет нитями чата (объекты Session), обрабатывая их инициацию, запись и завершение, в то время как MemoryService контролирует хранение и извлечение долгосрочных знаний (Memory).
Как SessionService, так и MemoryService предлагают различные варианты конфигурации, позволяя пользователям выбирать методы хранения в зависимости от потребностей приложения. Доступны варианты в памяти для целей тестирования, хотя данные не будут сохраняться при перезапусках. Для постоянного хранения и масштабируемости ADK также поддерживает базы данных и облачные сервисы.
Session: Отслеживание каждого чата
Объект Session в ADK предназначен для отслеживания и управления индивидуальными нитями чата. При инициации разговора с агентом SessionService генерирует объект Session, представленный как google.adk.sessions.Session. Этот объект инкапсулирует все данные, релевантные для конкретной нити разговора, включая уникальные идентификаторы (id, app_name, user_id), хронологическую запись событий как объекты Event, область хранения для временных данных, специфичных для сессии, известную как state, и временную метку, указывающую на последнее обновление (last_update_time). Разработчики обычно взаимодействуют с объектами Session косвенно через SessionService. SessionService отвечает за управление жизненным циклом сессий разговора, что включает инициацию новых сессий, возобновление предыдущих сессий, запись активности сессии (включая обновления состояния), идентификацию активных сессий и управление удалением данных сессии. ADK предоставляет несколько реализаций SessionService с различными механизмами хранения для истории сессий и временных данных, такие как InMemorySessionService, который подходит для тестирования, но не обеспечивает постоянство данных при перезапусках приложения.
# Пример: Использование InMemorySessionService
# Подходит для локальной разработки и тестирования, где постоянство данных
# при перезапуске приложения не требуется.
from google.adk.sessions import InMemorySessionService
session_service = InMemorySessionService()Затем есть DatabaseSessionService, если вы хотите надежное сохранение в базу данных, которой вы управляете.
# Пример: Использование DatabaseSessionService
# Подходит для продакшна или разработки, требующей постоянного хранения.
# Необходимо настроить URL базы данных (например, для SQLite, PostgreSQL и т.д.).
# Требует: pip install google-adk[sqlalchemy] и драйвер базы данных (например, psycopg2 для PostgreSQL)
from google.adk.sessions import DatabaseSessionService
# Пример использования локального файла SQLite:
db_url = "sqlite:///./my_agent_data.db"
session_service = DatabaseSessionService(db_url=db_url)Кроме того, есть VertexAiSessionService, который использует инфраструктуру Vertex AI для масштабируемого продакшна в Google Cloud.
# Пример: Использование VertexAiSessionService
# Подходит для масштабируемого продакшна на Google Cloud Platform, используя
# инфраструктуру Vertex AI для управления сессиями.
# Требует: pip install google-adk[vertexai] и настройку/аутентификацию GCP
from google.adk.sessions import VertexAiSessionService
PROJECT_ID = "your-gcp-project-id" # Замените на ваш ID проекта GCP
LOCATION = "us-central1" # Замените на желаемое расположение GCP
# app_name, используемый с этим сервисом, должен соответствовать ID или имени Reasoning Engine
REASONING_ENGINE_APP_NAME = "projects/your-gcp-project-id/locations/us-central1/reasoningEngines/your-engine-id" # Замените на имя ресурса вашего Reasoning Engine
session_service = VertexAiSessionService(project=PROJECT_ID, location=LOCATION)
# При использовании этого сервиса передавайте REASONING_ENGINE_APP_NAME в методы сервиса:
# session_service.create_session(app_name=REASONING_ENGINE_APP_NAME, ...)
# session_service.get_session(app_name=REASONING_ENGINE_APP_NAME, ...)
# session_service.append_event(session, event, app_name=REASONING_ENGINE_APP_NAME)
# session_service.delete_session(app_name=REASONING_ENGINE_APP_NAME, ...)Выбор подходящего SessionService критически важен, поскольку он определяет, как история взаимодействий агента и временные данные хранятся и их постоянство.
Каждый обмен сообщениями включает циклический процесс: получается сообщение, Runner извлекает или устанавливает Session с использованием SessionService, агент обрабатывает сообщение, используя контекст Session (состояние и исторические взаимодействия), агент генерирует ответ и может обновить состояние, Runner инкапсулирует это как Event, и метод session_service.append_event записывает новое событие и обновляет состояние в хранилище. Session затем ожидает следующего сообщения. В идеале метод delete_session используется для завершения сессии, когда взаимодействие заканчивается. Этот процесс иллюстрирует, как SessionService поддерживает непрерывность, управляя историей и временными данными, специфичными для Session.
State: Блокнот Session
В ADK каждая Session, представляющая нить чата, включает компонент state, подобный временной рабочей памяти агента на время этого конкретного разговора. Пока session.events регистрирует всю историю чата, session.state хранит и обновляет динамические точки данных, релевантные для активного чата.
По сути, session.state работает как словарь, хранящий данные в виде пар ключ-значение. Его основная функция — позволить агенту сохранять и управлять деталями, необходимыми для связного диалога, такими как пользовательские предпочтения, прогресс задач, инкрементальный сбор данных или условные флаги, влияющие на последующие действия агента.
Структура state состоит из строковых ключей, связанных со значениями сериализуемых типов Python, включая строки, числа, булевы значения, списки и словари, содержащие эти базовые типы. State является динамичным, развивающимся на протяжении разговора. Постоянство этих изменений зависит от настроенного SessionService.
Организация state может быть достигнута с использованием префиксов ключей для определения области данных и постоянства. Ключи без префиксов специфичны для сессии.
- Префикс
user:связывает данные с ID пользователя во всех сессиях. - Префикс
app:обозначает данные, разделяемые между всеми пользователями приложения. - Префикс
temp:указывает данные, действительные только для текущего хода обработки и не сохраняемые постоянно.
Агент получает доступ ко всем данным state через единый словарь session.state. SessionService обрабатывает извлечение, слияние и постоянство данных. State должен обновляться при добавлении Event в историю сессии через session_service.append_event(). Это обеспечивает точное отслеживание, правильное сохранение в постоянных сервисах и безопасную обработку изменений состояния.
- Простой способ: Использование output_key (для текстовых ответов агента): Это самый простой метод, если вы просто хотите сохранить финальный текстовый ответ агента прямо в state. Когда вы настраиваете свой LlmAgent, просто укажите output_key, который хотите использовать. Runner видит это и автоматически создает необходимые действия для сохранения ответа в state при добавлении события. Рассмотрим пример кода, демонстрирующий обновление state через output_key.
# Импорт необходимых классов из Google Agent Developer Kit (ADK)
from google.adk.agents import LlmAgent
from google.adk.sessions import InMemorySessionService, Session
from google.adk.runners import Runner
from google.genai.types import Content, Part
# Определение LlmAgent с output_key.
greeting_agent = LlmAgent(
name="Greeter",
model="gemini-2.0-flash",
instruction="Generate a short, friendly greeting.",
output_key="last_greeting"
)
# --- Настройка Runner и Session ---
app_name, user_id, session_id = "state_app", "user1", "session1"
session_service = InMemorySessionService()
runner = Runner(
agent=greeting_agent,
app_name=app_name,
session_service=session_service
)
session = session_service.create_session(
app_name=app_name,
user_id=user_id,
session_id=session_id
)
print(f"Initial state: {session.state}")
# --- Запуск агента ---
user_message = Content(parts=[Part(text="Hello")])
print("\n--- Running the agent ---")
for event in runner.run(
user_id=user_id,
session_id=session_id,
new_message=user_message
):
if event.is_final_response():
print("Agent responded.")
# --- Проверка обновленного состояния ---
# Правильно проверяем состояние *после* того, как runner закончил обработку всех событий.
updated_session = session_service.get_session(app_name, user_id, session_id)
print(f"\nState after agent run: {updated_session.state}")За кулисами Runner видит ваш output_key и автоматически создает необходимые действия с state_delta при вызове append_event.
- Стандартный способ: Использование EventActions.state_delta (для более сложных обновлений): Для случаев, когда вам нужно делать более сложные вещи — например, обновлять несколько ключей одновременно, сохранять вещи, которые не являются просто текстом, нацеливаться на конкретные области, такие как user: или app:, или делать обновления, которые не связаны с финальным текстовым ответом агента — вы вручную создадите словарь ваших изменений состояния (state_delta) и включите его в EventActions события, которое вы добавляете. Рассмотрим один пример:
import time
from google.adk.tools.tool_context import ToolContext
from google.adk.sessions import InMemorySessionService
# --- Определение рекомендуемого подхода на основе инструментов ---
def log_user_login(tool_context: ToolContext) -> dict:
"""
Обновляет состояние сессии при событии входа пользователя.
Этот инструмент инкапсулирует все изменения состояния, связанные с входом пользователя.
Args:
tool_context: Автоматически предоставляется ADK, дает доступ к состоянию сессии.
Returns:
Словарь, подтверждающий успешность действия.
"""
# Доступ к состоянию напрямую через предоставленный контекст.
state = tool_context.state
# Получение текущих значений или значений по умолчанию, затем обновление состояния.
# Это намного чище и локализует логику.
login_count = state.get("user:login_count", 0) + 1
state["user:login_count"] = login_count
state["task_status"] = "active"
state["user:last_login_ts"] = time.time()
state["temp:validation_needed"] = True
print("State updated from within the `log_user_login` tool.")
return {
"status": "success",
"message": f"User login tracked. Total logins: {login_count}."
}
# --- Демонстрация использования ---
# В реальном приложении LLM Agent решил бы вызвать этот инструмент.
# Здесь мы симулируем прямой вызов для демонстрационных целей.
# 1. Настройка
session_service = InMemorySessionService()
app_name, user_id, session_id = "state_app_tool", "user3", "session3"
session = session_service.create_session(
app_name=app_name,
user_id=user_id,
session_id=session_id,
state={"user:login_count": 0, "task_status": "idle"}
)
print(f"Initial state: {session.state}")
# 2. Симуляция вызова инструмента (в реальном приложении это делает ADK Runner)
# Мы создаем ToolContext вручную только для этого автономного примера.
from google.adk.tools.tool_context import InvocationContext
mock_context = ToolContext(
invocation_context=InvocationContext(
app_name=app_name, user_id=user_id, session_id=session_id,
session=session, session_service=session_service
)
)
# 3. Выполнение инструмента
log_user_login(mock_context)
# 4. Проверка обновленного состояния
updated_session = session_service.get_session(app_name, user_id, session_id)
print(f"State after tool execution: {updated_session.state}")
# Ожидаемый вывод покажет то же изменение состояния, что и в случае "До",
# но организация кода значительно чище и более надежна.Этот код демонстрирует подход на основе инструментов для управления состоянием пользовательской сессии в приложении. Он определяет функцию log_user_login, которая действует как инструмент. Этот инструмент отвечает за обновление состояния сессии при входе пользователя.
Функция принимает объект ToolContext, предоставляемый ADK, для доступа и изменения словаря состояния сессии. Внутри инструмента она увеличивает user:login_count, устанавливает task_status в "active", записывает user:last_login_ts (временную метку) и добавляет временный флаг temp:validation_needed.
Демонстрационная часть кода симулирует, как этот инструмент будет использоваться. Она настраивает сервис сессий в памяти и создает начальную сессию с некоторым предопределенным состоянием. Затем вручную создается ToolContext для имитации среды, в которой ADK Runner выполнил бы инструмент. Функция log_user_login вызывается с этим мок-контекстом. Наконец, код снова получает сессию, чтобы показать, что состояние было обновлено выполнением инструмента. Цель состоит в том, чтобы показать, как инкапсуляция изменений состояния в инструментах делает код чище и более организованным по сравнению с прямым манипулированием состояния вне инструментов.
Обратите внимание, что прямое изменение словаря session.state после получения сессии настоятельно не рекомендуется, поскольку это обходит стандартный механизм обработки событий. Такие прямые изменения не будут записаны в историю событий сессии, могут не быть сохранены выбранным SessionService, могут привести к проблемам конкурентности и не обновят важные метаданные, такие как временные метки. Рекомендуемые методы обновления состояния сессии — использование параметра output_key на LlmAgent (специально для финальных текстовых ответов агента) или включение изменений состояния в EventActions.state_delta при добавлении события через session_service.append_event(). session.state должен в основном использоваться для чтения существующих данных.
В заключение, при разработке вашего состояния держите его простым, используйте базовые типы данных, давайте вашим ключам ясные имена и правильно используйте префиксы, избегайте глубокой вложенности и всегда обновляйте состояние, используя процесс append_event.
Memory: Долгосрочные знания с MemoryService
В агентных системах компонент Session поддерживает запись текущей истории чата (события) и временных данных (состояние), специфичных для одного разговора. Однако для агентов, чтобы сохранять информацию через множественные взаимодействия или получать доступ к внешним данным, необходимо управление долгосрочными знаниями. Это обеспечивается MemoryService.
# Пример: Использование InMemoryMemoryService
# Подходит для локальной разработки и тестирования, где постоянство данных
# при перезапуске приложения не требуется.
# Содержимое памяти теряется при остановке приложения.
from google.adk.memory import InMemoryMemoryService
memory_service = InMemoryMemoryService()Session и State можно концептуализировать как краткосрочную память для одной сессии чата, тогда как долгосрочные знания, управляемые MemoryService, функционируют как постоянное и поисковое хранилище. Это хранилище может содержать информацию из множественных прошлых взаимодействий или внешних источников. MemoryService, как определено интерфейсом BaseMemoryService, устанавливает стандарт для управления этими поисковыми долгосрочными знаниями. Его основные функции включают добавление информации, которое включает извлечение содержимого из сессии и его сохранение с использованием метода add_session_to_memory, и извлечение информации, которое позволяет агенту запросить хранилище и получить релевантные данные с использованием метода search_memory.
ADK предлагает несколько реализаций для создания этого хранилища долгосрочных знаний. InMemoryMemoryService предоставляет временное решение хранения, подходящее для целей тестирования, но данные не сохраняются при перезапусках приложения. Для продакшн-сред обычно используется VertexAiRagMemoryService. Этот сервис использует службу Retrieval Augmented Generation (RAG) Google Cloud, обеспечивая масштабируемые, постоянные возможности семантического поиска (также обратитесь к главе 14 о RAG).
# Пример: Использование VertexAiRagMemoryService
# Подходит для масштабируемого продакшна на GCP, используя
# Vertex AI RAG (Retrieval Augmented Generation) для постоянной,
# поисковой памяти.
# Требует: pip install google-adk[vertexai], настройку/аутентификацию GCP
# и Vertex AI RAG Corpus.
from google.adk.memory import VertexAiRagMemoryService
# Имя ресурса вашего Vertex AI RAG Corpus
RAG_CORPUS_RESOURCE_NAME = "projects/your-gcp-project-id/locations/us-central1/ragCorpora/your-corpus-id" # Замените на имя ресурса вашего Corpus
# Дополнительная конфигурация для поведения извлечения
SIMILARITY_TOP_K = 5 # Количество топ-результатов для извлечения
VECTOR_DISTANCE_THRESHOLD = 0.7 # Порог для векторного сходства
memory_service = VertexAiRagMemoryService(
rag_corpus=RAG_CORPUS_RESOURCE_NAME,
similarity_top_k=SIMILARITY_TOP_K,
vector_distance_threshold=VECTOR_DISTANCE_THRESHOLD
)
# При использовании этого сервиса методы, такие как add_session_to_memory
# и search_memory, будут взаимодействовать с указанным Vertex AI
# RAG Corpus.Практический код: Управление памятью в LangChain и LangGraph
В LangChain и LangGraph память является критическим компонентом для создания интеллектуальных и естественно ощущаемых разговорных приложений. Она позволяет агенту ИИ запоминать информацию из прошлых взаимодействий, учиться на обратной связи и адаптироваться к пользовательским предпочтениям. Функция памяти LangChain обеспечивает основу для этого, ссылаясь на сохраненную историю для обогащения текущих промптов и затем записывая последний обмен для будущего использования. По мере того, как агенты обрабатывают более сложные задачи, эта возможность становится необходимой как для эффективности, так и для удовлетворения пользователей.
Краткосрочная память: Это область действия потока, означающая, что она отслеживает продолжающийся разговор в рамках одной сессии или потока. Она обеспечивает немедленный контекст, но полная история может бросить вызов контекстному окну LLM, потенциально приводя к ошибкам или плохой производительности. LangGraph управляет краткосрочной памятью как частью состояния агента, которое сохраняется через checkpointer, позволяя возобновить поток в любое время.
Долгосрочная память: Это хранит пользовательские или уровневые данные приложения через сессии и разделяется между разговорными потоками. Она сохраняется в пользовательских "пространствах имен" и может быть вызвана в любое время в любом потоке. LangGraph предоставляет хранилища для сохранения и вызова долгосрочных воспоминаний, позволяя агентам сохранять знания неопределенно долго.
LangChain предоставляет несколько инструментов для управления историей разговоров, от ручного контроля до автоматизированной интеграции в цепочки.
ChatMessageHistory: Ручное управление памятью. Для прямого и простого контроля над историей разговора вне формальной цепочки класс ChatMessageHistory идеален. Он позволяет ручное отслеживание обменов диалогами.
from langchain.memory import ChatMessageHistory
# Инициализация объекта истории
history = ChatMessageHistory()
# Добавление сообщений пользователя и ИИ
history.add_user_message("Я направляюсь в Нью-Йорк на следующей неделе.")
history.add_ai_message("Отлично! Это фантастический город.")
# Доступ к списку сообщений
print(history.messages)ConversationBufferMemory: Автоматизированная память для цепочек. Для интеграции памяти непосредственно в цепочки ConversationBufferMemory является распространенным выбором. Она содержит буфер разговора и делает его доступным для вашего промпта. Ее поведение может быть настроено с помощью двух ключевых параметров:
memory_key: Строка, которая указывает имя переменной в вашем промпте, которая будет содержать историю чата. По умолчанию "history".return_messages: Булево значение, которое диктует формат истории.- Если False (по умолчанию), оно возвращает одну отформатированную строку, которая идеальна для стандартных LLM.
- Если True, оно возвращает список объектов сообщений, что является рекомендуемым форматом для чат-моделей.
from langchain.memory import ConversationBufferMemory
# Инициализация памяти
memory = ConversationBufferMemory()
# Сохранение хода разговора
memory.save_context({"input": "Какая погода?"}, {"output": "Сегодня солнечно."})
# Загрузка памяти как строки
print(memory.load_memory_variables({}))Интеграция этой памяти в LLMChain позволяет модели получать доступ к истории разговора и предоставлять контекстуально релевантные ответы:
from langchain_openai import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
# 1. Определение LLM и Prompt
llm = OpenAI(temperature=0)
template = """Вы полезный туристический агент.
Предыдущий разговор:
{history}
Новый вопрос: {question}
Ответ:"""
prompt = PromptTemplate.from_template(template)
# 2. Конфигурация памяти
# memory_key "history" соответствует переменной в промпте
memory = ConversationBufferMemory(memory_key="history")
# 3. Построение цепочки
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 4. Запуск разговора
response = conversation.predict(question="Я хочу забронировать рейс.")
print(response)
response = conversation.predict(question="Кстати, меня зовут Сэм.")
print(response)
response = conversation.predict(question="Как меня звали снова?")
print(response)Для улучшенной эффективности с чат-моделями рекомендуется использовать структурированный список объектов сообщений, установив return_messages=True.
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# 1. Определение чат-модели и промпта
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template("Вы дружелюбный помощник."),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# 2. Конфигурация памяти
# return_messages=True необходимо для чат-моделей
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
# 3. Построение цепочки
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory)
# 4. Запуск разговора
response = conversation.predict(question="Привет, я Джейн.")
print(response)
response = conversation.predict(question="Помните ли вы мое имя?")
print(response)Типы долгосрочной памяти: Долгосрочная память позволяет системам сохранять информацию через различные разговоры, обеспечивая более глубокий уровень контекста и персонализации. Она может быть разбита на три типа, аналогичных человеческой памяти:
Семантическая память: Запоминание фактов: Это включает сохранение конкретных фактов и концепций, таких как пользовательские предпочтения или знания предметной области. Она используется для обоснования ответов агента, приводя к более персонализированным и релевантным взаимодействиям. Эта информация может управляться как постоянно обновляемый пользовательский "профиль" (JSON-документ) или как "коллекция" индивидуальных фактических документов.
Эпизодическая память: Запоминание опыта: Это включает вспоминание прошлых событий или действий. Для агентов ИИ эпизодическая память часто используется для запоминания того, как выполнить задачу. На практике она часто реализуется через few-shot example prompting, где агент учится на прошлых успешных последовательностях взаимодействий для правильного выполнения задач.
Процедурная память: Запоминание правил: Это память о том, как выполнять задачи — основные инструкции и поведения агента, часто содержащиеся в его системном промпте. Для агентов обычно изменять свои собственные промпты для адаптации и улучшения. Эффективная техника — "Рефлексия", где агент получает промпт со своими текущими инструкциями и недавними взаимодействиями, затем просят уточнить свои собственные инструкции.
Ниже псевдокод, демонстрирующий, как агент может использовать рефлексию для обновления своей процедурной памяти, хранящейся в LangGraph BaseStore:
# Узел, который обновляет инструкции агента
def update_instructions(state: State, store: BaseStore):
namespace = ("instructions",)
# Получение текущих инструкций из хранилища
current_instructions = store.search(namespace)[0]
# Создание промпта для запроса LLM рефлексировать над разговором
# и генерировать новые, улучшенные инструкции
prompt = prompt_template.format(
instructions=current_instructions.value["instructions"],
conversation=state["messages"]
)
# Получение новых инструкций от LLM
output = llm.invoke(prompt)
new_instructions = output['new_instructions']
# Сохранение обновленных инструкций обратно в хранилище
store.put(("agent_instructions",), "agent_a", {"instructions": new_instructions})
# Узел, который использует инструкции для генерации ответа
def call_model(state: State, store: BaseStore):
namespace = ("agent_instructions", )
# Извлечение последних инструкций из хранилища
instructions = store.get(namespace, key="agent_a")[0]
# Использование извлеченных инструкций для форматирования промпта
prompt = prompt_template.format(instructions=instructions.value["instructions"])
# ... логика приложения продолжаетсяLangGraph хранит долгосрочные воспоминания как JSON-документы в хранилище. Каждое воспоминание организовано под пользовательским пространством имен (как папка) и отдельным ключом (как имя файла). Эта иерархическая структура позволяет легкую организацию и извлечение информации. Следующий код демонстрирует, как использовать InMemoryStore для размещения, получения и поиска воспоминаний.
from langgraph.store.memory import InMemoryStore
# Заполнитель для реальной функции встраивания
def embed(texts: list[str]) -> list[list[float]]:
# В реальном приложении используйте подходящую модель встраивания
return [[1.0, 2.0] for _ in texts]
# Инициализация хранилища в памяти. Для продакшна используйте хранилище на основе базы данных.
store = InMemoryStore(index={"embed": embed, "dims": 2})
# Определение пространства имен для конкретного пользователя и контекста приложения
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
# 1. Размещение воспоминания в хранилище
store.put(
namespace,
"a-memory", # Ключ для этого воспоминания
{
"rules": [
"Пользователь любит короткий, прямой язык",
"Пользователь говорит только на английском и python",
],
"my-key": "my-value",
},
)
# 2. Получение воспоминания по его пространству имен и ключу
item = store.get(namespace, "a-memory")
print("Retrieved Item:", item)
# 3. Поиск воспоминаний в пространстве имен, фильтрация по содержанию
# и сортировка по векторному сходству с запросом.
items = store.search(
namespace,
filter={"my-key": "my-value"},
query="языковые предпочтения"
)
print("Search Results:", items)Vertex Memory Bank
Memory Bank — управляемый сервис в Vertex AI Agent Engine, предоставляющий агентам постоянную долгосрочную память. Сервис использует модели Gemini для асинхронного анализа историй разговоров для извлечения ключевых фактов и пользовательских предпочтений.
Эта информация хранится постоянно, организована по определенной области, такой как ID пользователя, и интеллектуально обновляется для консолидации новых данных и разрешения противоречий. При начале новой сессии агент извлекает релевантные воспоминания через полный вызов данных или поиск по сходству с использованием встраиваний. Этот процесс позволяет агенту поддерживать непрерывность между сессиями и персонализировать ответы на основе вспоминаемой информации.
Runner агента взаимодействует с VertexAiMemoryBankService, который сначала инициализируется. Этот сервис обрабатывает автоматическое хранение воспоминаний, генерируемых во время разговоров агента. Каждое воспоминание помечается уникальным USER_ID и APP_NAME, обеспечивая точное извлечение в будущем.
from google.adk.memory import VertexAiMemoryBankService
agent_engine_id = agent_engine.api_resource.name.split("/")[-1]
memory_service = VertexAiMemoryBankService(
project="PROJECT_ID",
location="LOCATION",
agent_engine_id=agent_engine_id
)
session = await session_service.get_session(
app_name=app_name,
user_id="USER_ID",
session_id=session.id
)
await memory_service.add_session_to_memory(session)Memory Bank предлагает бесшовную интеграцию с Google ADK, обеспечивая немедленный готовый к использованию опыт. Для пользователей других агентных фреймворков, таких как LangGraph и CrewAI, Memory Bank также предлагает поддержку через прямые API-вызовы. Онлайн примеры кода, демонстрирующие эти интеграции, легко доступны для заинтересованных читателей.
Краткий обзор
Что: Агентные системы должны запоминать информацию из прошлых взаимодействий для выполнения сложных задач и предоставления связных опытов. Без механизма памяти агенты являются состояниями без состояния, неспособными поддерживать контекст разговора, учиться на опыте или персонализировать ответы для пользователей. Это принципиально ограничивает их простыми одноразовыми взаимодействиями, не справляясь с многошаговыми процессами или развивающимися потребностями пользователей. Основная проблема заключается в том, как эффективно управлять как немедленной временной информацией одного разговора, так и обширными постоянными знаниями, собранными со временем.
Почему: Стандартизированное решение — реализация двухкомпонентной системы памяти, которая различает краткосрочное и долгосрочное хранение. Краткосрочная контекстная память содержит недавние данные взаимодействий в контекстном окне LLM для поддержания потока разговора. Для информации, которая должна сохраняться, решения долгосрочной памяти используют внешние базы данных, часто векторные хранилища, для эффективного семантического извлечения. Агентные фреймворки, такие как Google ADK, предоставляют специфические компоненты для управления этим, такие как Session для нити разговора и State для ее временных данных. Специализированный MemoryService используется для интерфейса с базой долгосрочных знаний, позволяя агенту извлекать и включать релевантную прошлую информацию в его текущий контекст.
Правило большого пальца: Используйте этот шаблон, когда агенту нужно делать больше, чем отвечать на один вопрос. Это необходимо для агентов, которые должны поддерживать контекст на протяжении разговора, отслеживать прогресс в многошаговых задачах или персонализировать взаимодействия, вспоминая пользовательские предпочтения и историю. Реализуйте управление памятью, когда агент ожидается учиться или адаптироваться на основе прошлых успехов, неудач или вновь приобретенной информации.
Визуальное резюме
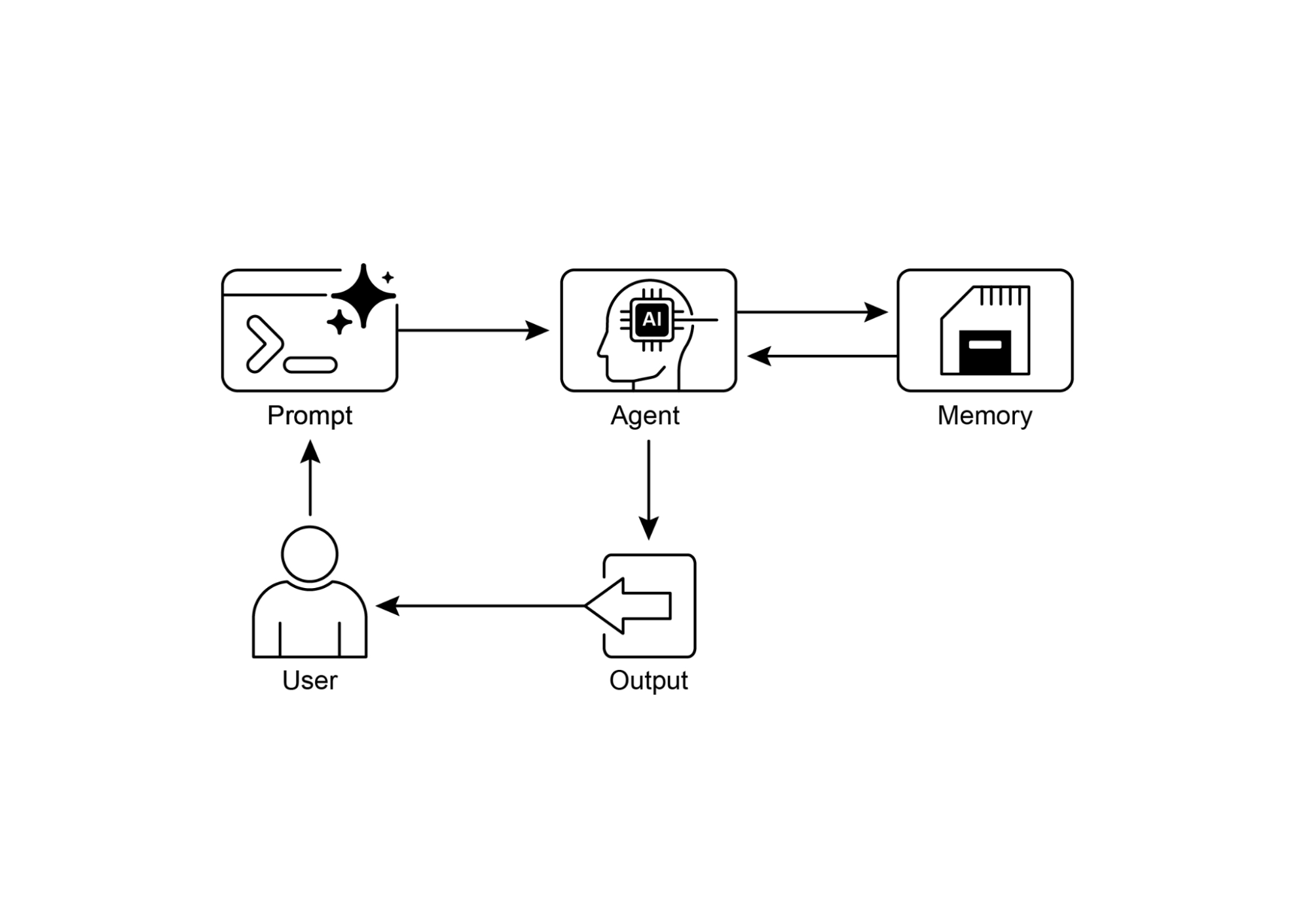
Рис.1: Шаблон проектирования управления памятью
Ключевые выводы
Чтобы быстро резюмировать основные моменты о управлении памятью:
- Память супер важна для агентов, чтобы отслеживать вещи, учиться и персонализировать взаимодействия.
- Разговорный ИИ полагается как на краткосрочную память для немедленного контекста в рамках одного чата, так и на долгосрочную память для постоянных знаний через множественные сессии.
- Краткосрочная память (немедленные вещи) является временной, часто ограниченной контекстным окном LLM или тем, как фреймворк передает контекст.
- Долгосрочная память (вещи, которые остаются) сохраняет информацию через различные чаты, используя внешнее хранение, такое как векторные базы данных, и доступна через поиск.
- Фреймворки, такие как ADK, имеют специфические части, такие как Session (нить чата), State (временные данные чата) и MemoryService (поисковые долгосрочные знания) для управления памятью.
- SessionService ADK обрабатывает всю жизнь сессии чата, включая ее историю (события) и временные данные (состояние).
- session.state ADK — это словарь для временных данных чата. Префиксы (user:, app:, temp:) говорят вам, где данные принадлежат и остаются ли они.
- В ADK вы должны обновлять состояние, используя EventActions.state_delta или output_key при добавлении событий, а не изменяя словарь состояния напрямую.
- MemoryService ADK предназначен для помещения информации в долгосрочное хранение и позволения агентам искать ее, часто используя инструменты.
- LangChain предлагает практические инструменты, такие как ConversationBufferMemory, для автоматического внедрения истории одного разговора в промпт, позволяя агенту вспоминать немедленный контекст.
- LangGraph обеспечивает продвинутую долгосрочную память, используя хранилище для сохранения и извлечения семантических фактов, эпизодических опытов или даже обновляемых процедурных правил через различные пользовательские сессии.
- Memory Bank — это управляемый сервис, который предоставляет агентам постоянную долгосрочную память, автоматически извлекая, сохраняя и вспоминая пользовательскую информацию для обеспечения персонализированных непрерывных разговоров через фреймворки, такие как Google ADK, LangGraph и CrewAI.
Заключение
Эта глава погрузилась в действительно важную работу управления памятью для агентных систем, показывая разницу между краткосрочным контекстом и знаниями, которые остаются надолго. Мы говорили о том, как эти типы памяти настроены и где вы их видите при создании более умных агентов, которые могут запоминать вещи. Мы детально рассмотрели, как Google ADK дает вам специфические части, такие как Session, State и MemoryService, для обработки этого. Теперь, когда мы рассмотрели, как агенты могут запоминать вещи, как краткосрочные, так и долгосрочные, мы можем перейти к тому, как они могут учиться и адаптироваться. Следующий шаблон "Обучение и адаптация" касается изменения агентом того, как он думает, действует или что он знает, все на основе новых опытов или данных.
Ссылки
Навигация
Назад: [Глава 7. Многоагентное сотрудничество](../../Часть 1/Глава 7. Многоагентное сотрудничество.md)
Вперед: Глава 9. Обучение и адаптация